UniPruneBench
Can Visual Input Be Compressed?
A Visual Token Compression Benchmark
for Large Multimodal Models
Introduction
Large multimodal models (LMMs) often suffer from severe inference inefficiency due to the large number of visual tokens introduced by image encoders. While recent token compression methods, such as pruning and merging, have shown promise in reducing redundancy, their evaluation remains fragmented and inconsistent. In this work, we present UniPruneBench, a unified and extensible benchmark for visual token pruning in multimodal LLMs. UniPruneBench provides standardized protocols across 6 ability dimensions and 10 datasets, covering 10 representative compression algorithms and 3 families of LMMs (LLaVA-v1.5, Intern-VL3, and Qwen2.5-VL). Beyond task accuracy, it incorporates system-level metrics such as runtime and prefilling latency to provide a holistic view. Our experiments uncover several key findings: (1) random pruning is a surprisingly strong baseline, (2) no single method consistently outperforms others across scenarios, (3) pruning sensitivity varies significantly across tasks, with OCR being most vulnerable, and (4) pruning ratio is the dominant factor governing performance degradation. We believe UniPruneBench will serve as a reliable foundation for future research on efficient multimodal modeling.
UniPruneBench
Overview of UniPruneBench, along with experimental results for representative pruning methods across various data scenarios.
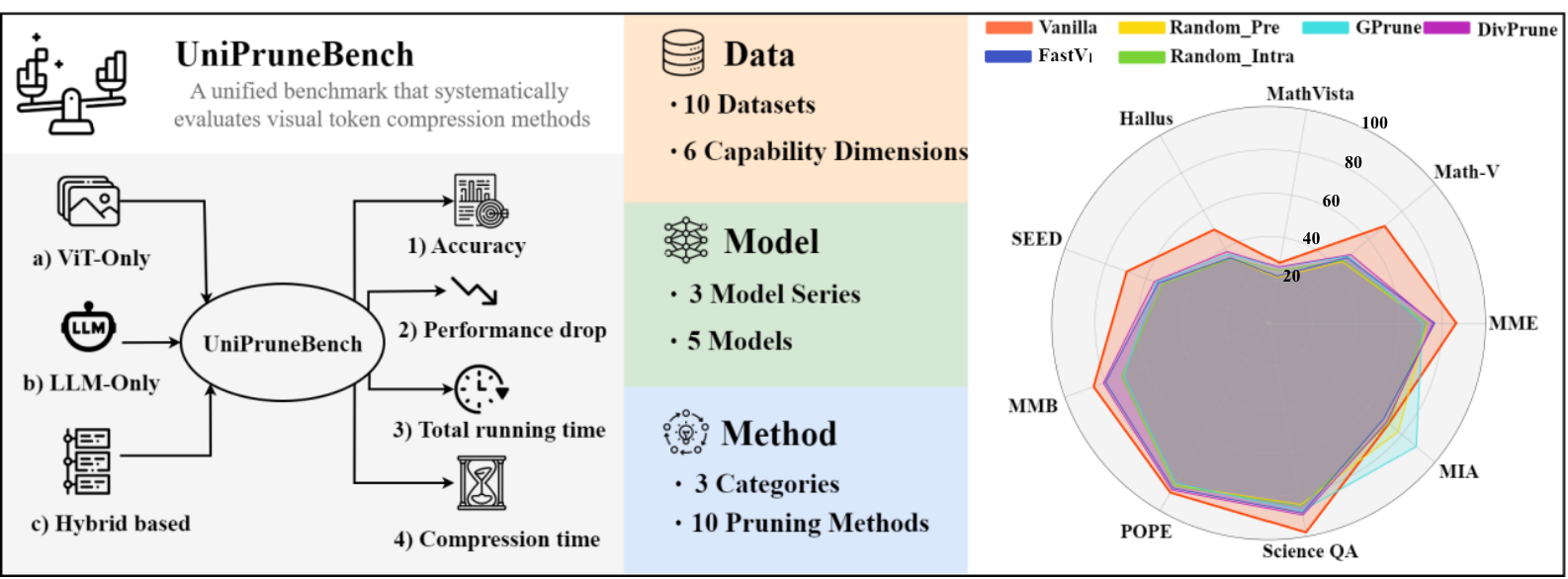
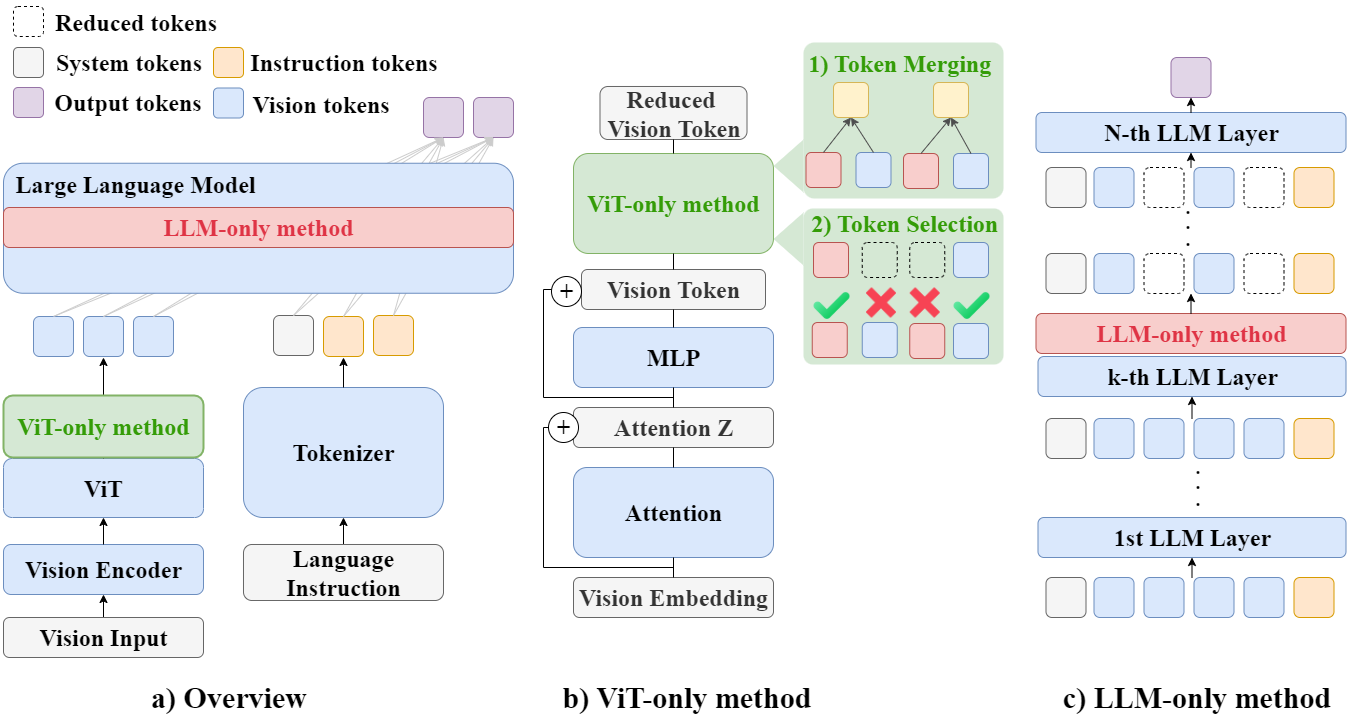
Figure 2 presents the UniPruneBench taxonomy of visual token pruning methods, categorized into ViT-only, LLM-only, and Hybrid approaches.
Results and Findings
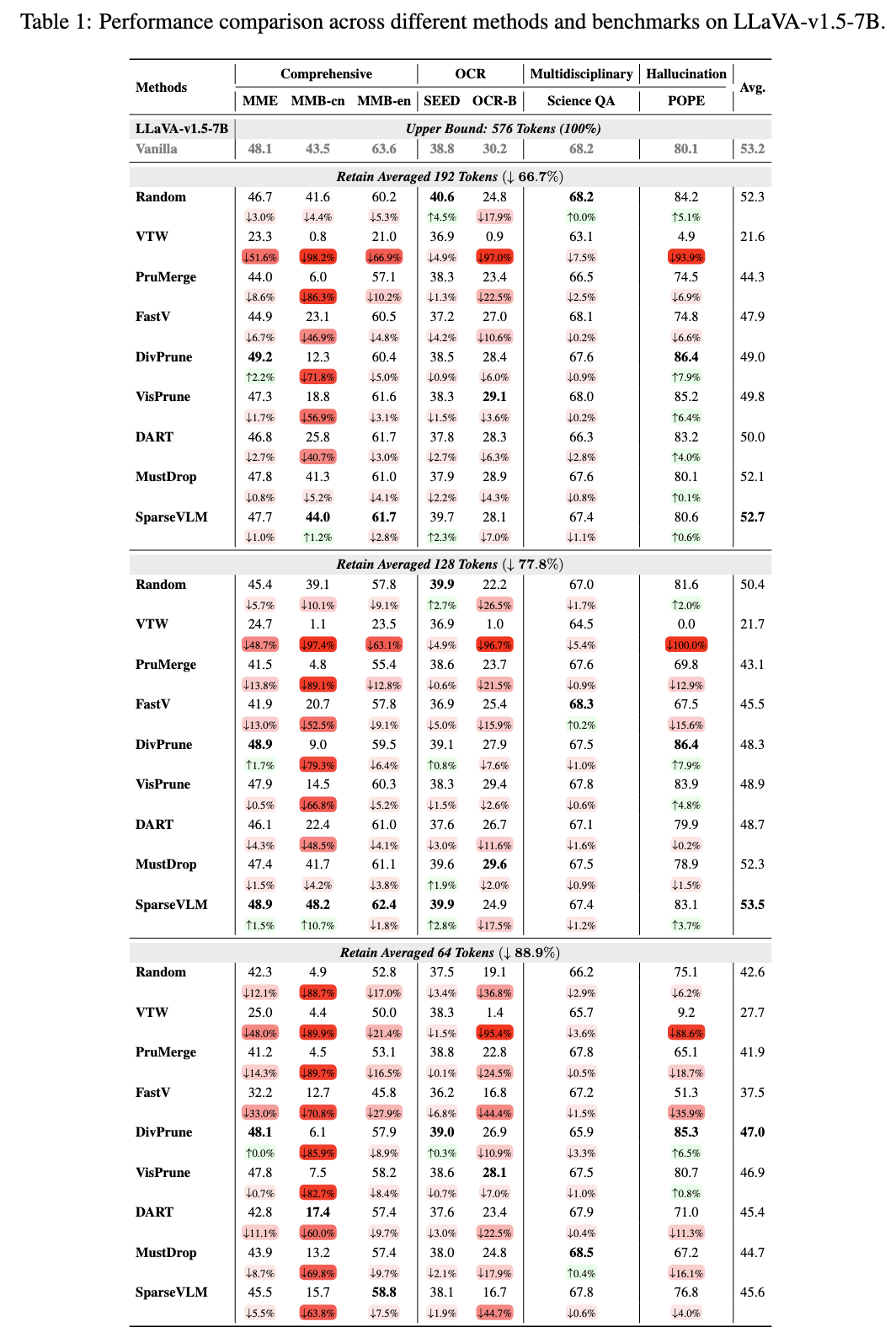
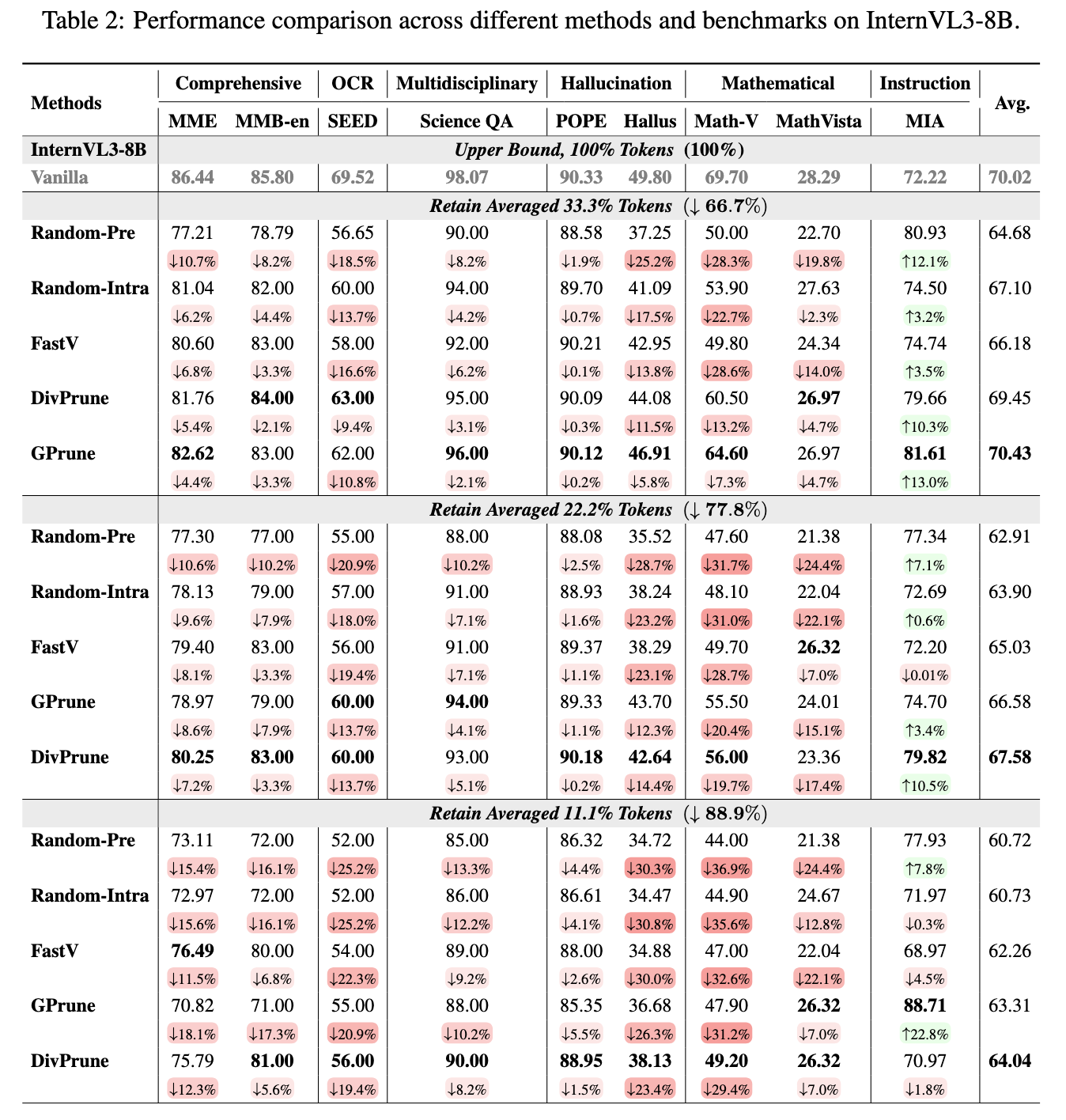
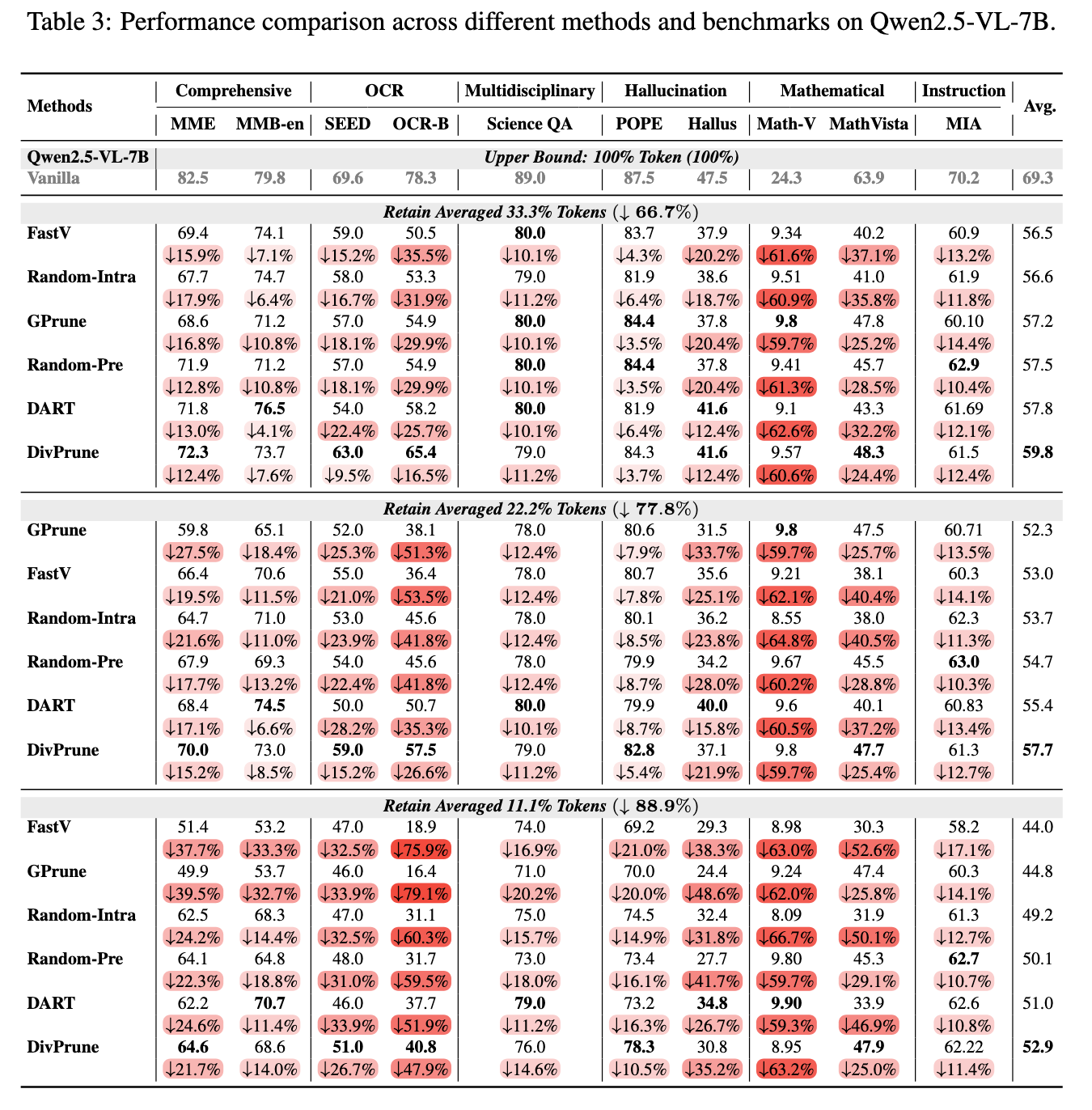
Analysis of Exploratory Results
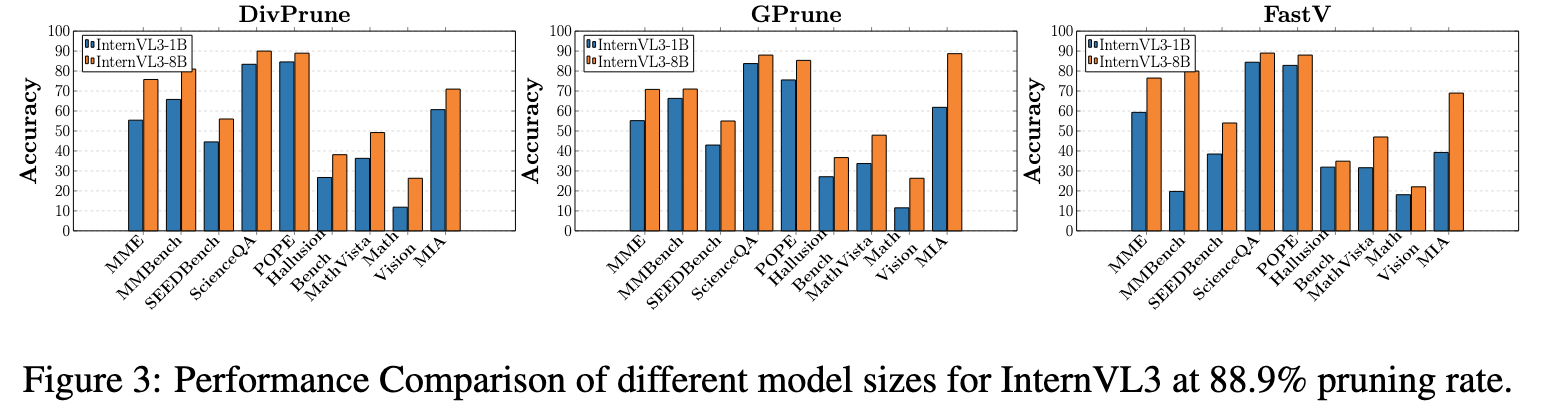
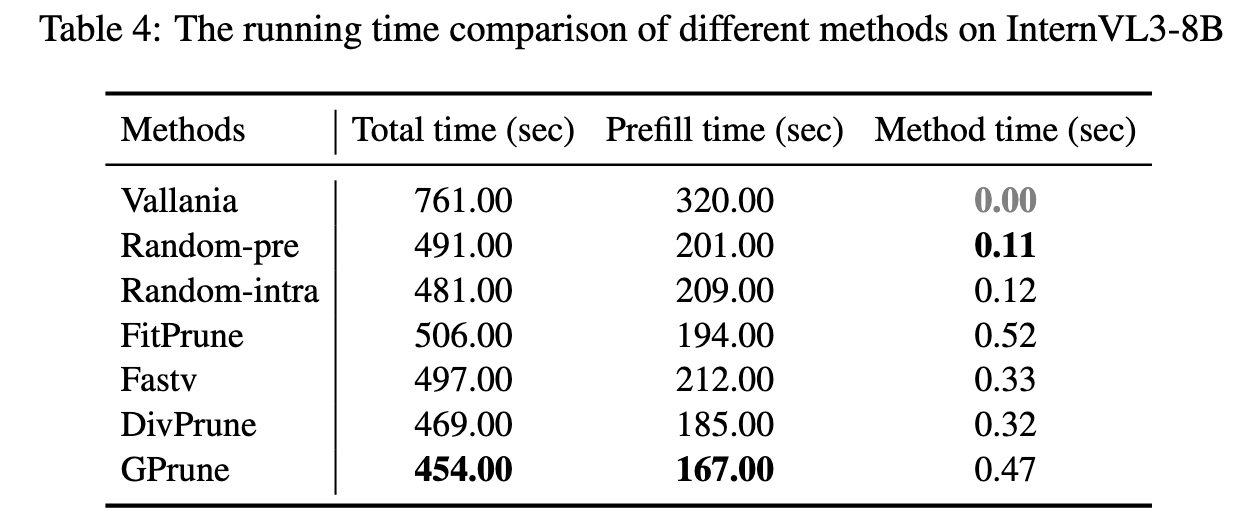
Case Studies
BibTeX
@article{peng2025can,
title={Can Visual Input Be Compressed? A Visual Token Compression Benchmark for Large Multimodal Models},
author={Peng, Tianfan and Du, Yuntao and Ji, Pengzhou and Dong, Shijie and Jiang, Kailin and Ma, Mingchuan and Tian, Yijun and Bi, Jinhe and Li, Qian and Du, Wei and others},
journal={arXiv preprint arXiv:2511.02650},
year={2025}
}